Terraformを利用したプロジェクトのディレクトリ構成とworkspaceの使い方

- 2019.11.18
こんにちは。 インフラエンジニアの久保です。 今回は、弊社で利用しているTerraformのディレクトリ構成について紹介します。 現在、Terraformを利用しているタイトルが複数存在します。 ただし、ワールド制の違いやマルチリージョン展開しているなど、プロジェクトによって要件 […]

こんにちは。 インフラエンジニアの久保です。 今回は、弊社で利用しているTerraformのディレクトリ構成について紹介します。 現在、Terraformを利用しているタイトルが複数存在します。 ただし、ワールド制の違いやマルチリージョン展開しているなど、プロジェクトによって要件 […]
初めまして。インフラエンジニアの田坂です。 先日OS Command Injection攻撃のテストをしてみたので内容を投稿したいと思います。 概要 セキュリティ等が正しく設定されていないLinuxサーバー上で運用されているアプリケーションに対して細工したURLを利用して、OS […]
こんにちは!インフラチームの川田です。 業務では社内ネットワーク構築・運用やツールの検証などしています。 本記事では、1月末から2月初頭にかけて行ったDB検証のベンチマーク結果をまとめたいと思います。 試験環境 今回は以下4つの環境を対象にMySQL 5.7互換のあるDBを構築し […]
はじめに 初めての人は初めまして、前回の記事(社内でエンジニア読書会をやってみた!)見てくれてる人こんにちは! 大阪スタジオ インフラチームの菅野明洋です。 業務では、大阪スタジオのサービスインフラを担当させていただいております。 今回は、2017年12月9日の土曜日に大阪で開催 […]
この記事を読むのに使用する時間の目安 = 5〜10分 你好! Magandang hapon po! こんにちわ! インフラチームの 小熊 です。 前回 から大分時間が経ってしまいましたが、Aimingのインフラ事情をいくつか紹介したいと思います。 TL;DR 必要だと思える時に […]
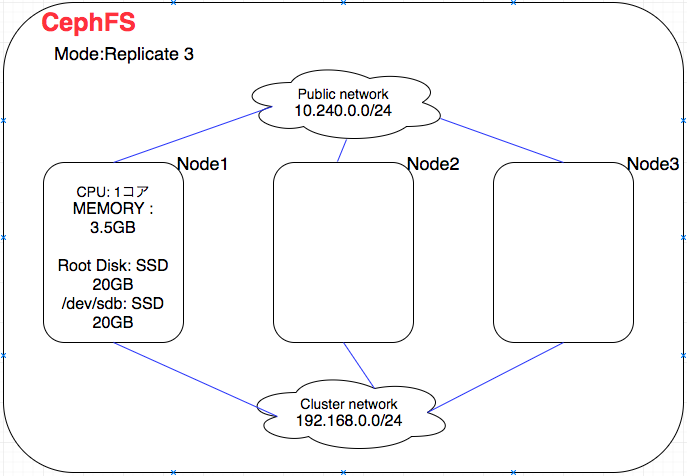
こんにちは! インフラエンジニアの趙です。 業務では、主にゲーム公式サイトのインフラまわりを担当しています。 弊社の一部公式サイトでは、WordPressを用いてオートスケールを導入しています。データ以外でステートフルな部分はCephFSにまかせています。 CephFSの運用につ […]
どうも、こんにちわ。 SNS幽霊部員ビリティ高めなOgumaです。 AimingではインフラをAll layerで担当しています。 先日6/16に、そのインフラに関係するMSP (Management Service Provider) である ハートビーツ さんに 数名で 遊び […]
はじめまして、大阪スタジオのサーバーエンジニアの太田と申します。 Webブラウザ版 『剣と魔法のログレス』(以下ログレス)は2011年にリリースして、おかげさまで今年で運営6年目になります。 そんなログレスも、そろそろマシンの老朽化やスペック不足が気になり始めたので、2017年3 […]
こんにちは、インフラエンジニアの久保です。 今回は、GCE(Google Compute Engine)のLocal SSDのチューニングとベンチマーク結果についてご紹介したいと思います。 Local SSDとは GCEではPersistent Disk(ネットワーク ディスク) […]
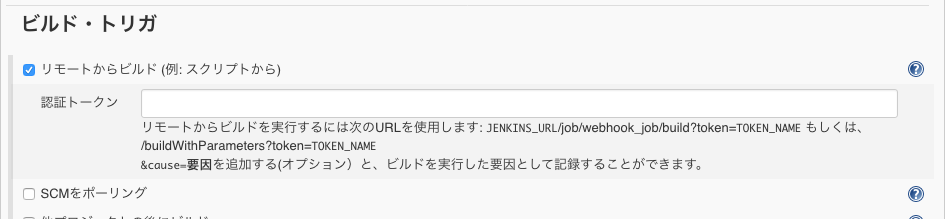
Jenkins と GitHub を連携させる Webhook について GitHub と Jenkins を連携させる機能のひとつに「Webhook」と呼ばれるものがあります。この Webhook をつかうことで、 GitHub 上で管理しているリポジトリにブランチを push […]
この記事を読むのに使用する時間の目安 = 15〜20分 インフラチームの小熊です。 前回(弊社インフラチームが参考にして実践しているITサービスフレームワークや利用しているOSS, Tool類の紹介をさせていただきました。)から大分空いてしまいましたが、今回は、そのツールやOSS […]
この記事を読むのに使用する時間の目安 = 15分 初めまして。 Aimingでインフラを担当している 小熊(oguma) と申します。 普段は、ウェブサイトの構築/運用管理や 東京と大阪のネットワーク設計/構築/運用管理、 backoffice toolなどのinfra/inho […]
はじめに 初めての人は初めまして、前回の記事(まべ☆てっく vol.1に登壇してきました!)見てくれてる人こんにちは! 大阪スタジオ インフラチームの菅野明洋です。 業務では、大阪スタジオのサービスインフラを担当させていただいております。 今回は、2016年10月2日の日曜日に大 […]
「ぐるぐるイーグル」チームでエンジニアをしている @takesato こと佐藤(たけ)です. 「ぐるぐるイーグル」では,エンジニアだけでなく企画もデザイナも github を使用して仕事をし,お互いレビューをするという環境ができあがっています. see. 【GGG#4】Aimin […]
こんにちは。15年度入社の新卒、大澤です。 私はインフラエンジニアとして Aiming に入社し、ほぼ毎日新しい技術やサービスに触れています( Git, Jenkins, Ansible, などなど… )。その中でも今回は、私が最近覚えた運用時に使う Ansible の一例を紹介 […]
はじめまして、エンジニアの古堀です。 Aimingではログの分析ツールとしてGoogleのBigQueryを利用しています。 ゲームプレイのログを集計、分析して機能開発、改善の指針として活用しています。 実際に運用に乗せてみるとログだけでは情報が足りず、ユーザー情報やマスターデー […]
こんにちは。リードソフトウェアエンジニアの保泉です。 2015年9月18日(金)にTGSフォーラム2015にて「これまでのオンラインゲーム、これからのオンラインゲーム」というセッションタイトルで、 弊社ゲームディレクター/ゲームデザイナーの水島と対談形式で講演をさせていただきまし […]
こんにちは。リードソフトウェアエンジニアの芝尾です。Aimingでは、タイトルのデータ分析・データ分析基盤の作成を行っております。 先日、Googleがモバイル・アプリ開発者向けに主催した「Google for モバイル・アプリ」というイベントでAiming社のGoogle Cl […]
こんにちは。リードソフトウェアエンジニアの保泉です。 2014年9月19日(金)にTGSフォーラム2014にて「Aimingのクラウド採用基準」というセッションタイトルで講演をさせていただきました。 セッションで使用したスライドを公開しましたのでお知らせいたします。 セッションで […]