
ログの収集基盤をサーバレス化した話
- 2017.10.04
- 未分類
初めまして、エンジニアの鴛海太一です。
主にデータ分析や、その基盤ツールを作るチームに所属しています。
今回は、アプリトラッキングツールから送られてくるログをBigQueryに入れるための機構をサーバレス化した話になります。
h2. サーバレス化の目的と以前の構成
以前の構成は以下のようなものでした。
!https://developer.aiming-inc.com/wp-content/uploads/2017/10/appsflyer.png!
この構成は、安定して1年ほど稼動していましたが、kubernetesの知識が必要で、メンテナンスがしにくいことが欠点でした。
h2. サーバレス化
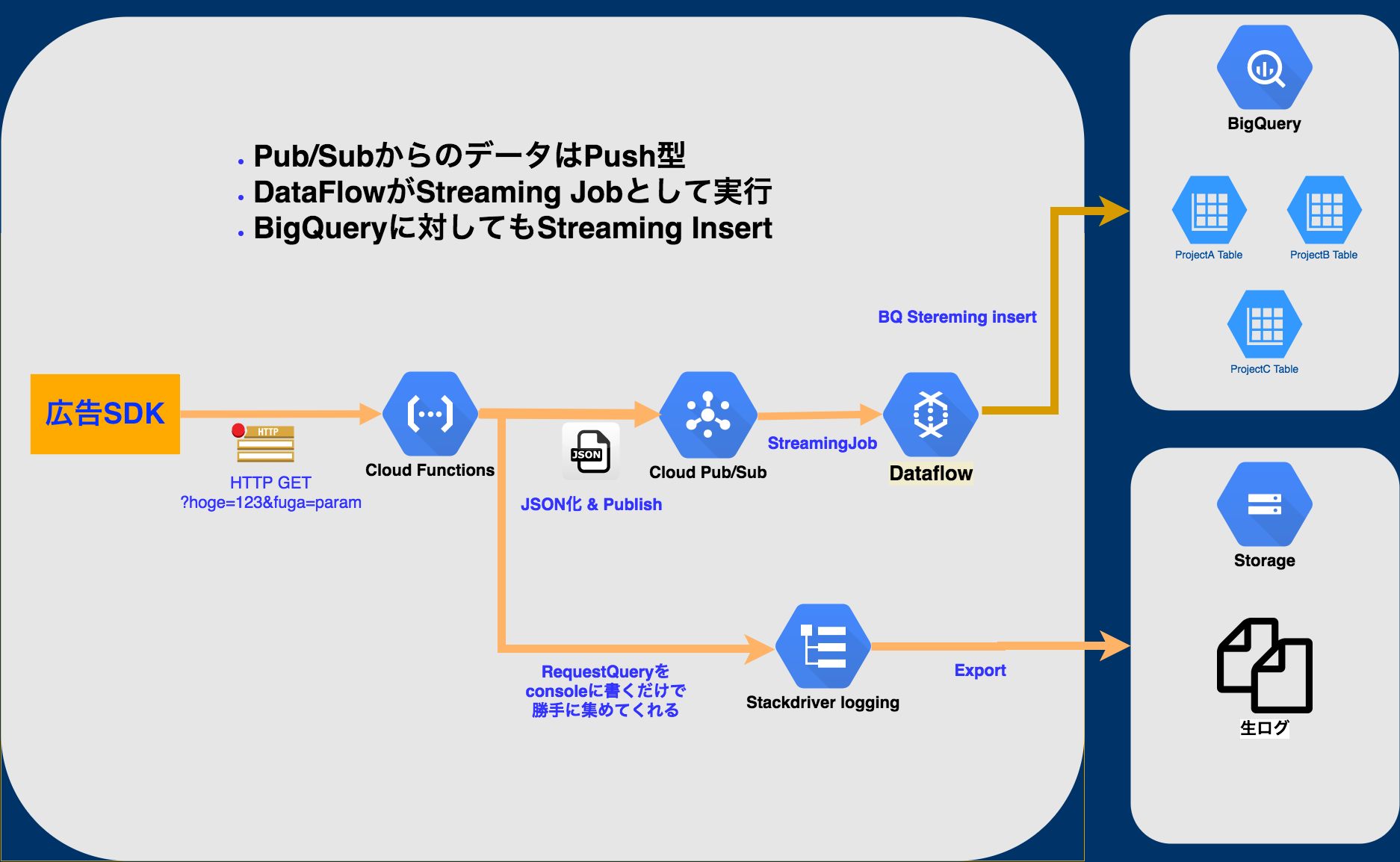
そこで、以下の図の様なマネージドサービスを使ったサーバレスアーキテクチャを構築しました。
!https://developer.aiming-inc.com/wp-content/uploads/2017/10/adjust.png!
h3. 概要
まず、Google Cloud Functionsはコールバックを受け取り、Google Pub/Subにpublishします。
その際に、標準出力でログを出しておき、それをGoogle Stackdriverで拾い、1時間おきにGoogle Cloud Storage(GCS)に保存します。
GCSに保存する理由は、何かしらの理由でログが欠損した場合に復元するためです。
Google Pub/SubにpublishされたログデータをDataflowでsubscribeし、不要なカラムの除去を行い、Google BigQueryの指定のテーブルにデータを挿入します。
h3. メリット
この構成にする利点は、無停止更新が行なえること、スケールが簡単なことです。
Cloud Functionsがダウンしている場合、広告SDK側はステータスコード200が返されるまでデータを保持するので、問題がありません。
Pub/Subがダウンしている場合も、同様にCloud Functionsでpublishが成功しなかった場合に、ステータスコード200を返さないようにすることで、広告SDK側でストアしてくれます。
Dataflowがダウンしている場合は、subscribeされないため、Pub/Subがデータを7日間まで保持してくれます(https://cloud.google.com/pubsub/quotas)。
この様に一部が停止しても問題なく動作するため、Cloud Functions、Pub/Sub、Dataflowの無停止更新が可能になります。
また、Pub/Subを間に挟むことによってデータ量が増大した場合にも対応できます。
h3. デメリット
逆にデメリットとしては、ベンダーロックインが発生すること、Dataflowの扱いが難しいことです。
Dataflowは、Pipelineという考え方を取り入れており、関数型のような考え方が要求されます。
他の部分でのコード量は少なく単純でしたが、Dataflowは少し複雑なものを書く必要がありました。
h2. おわりに
ログ収集の機構をサーバレス化した実例をお話ししました。
マネージドサービスを使うことによって、管理コストを減らすことが可能です。
また、Pub/SubやCloud Functionsは、料金的にも安くおさえられるのでオススメです。
-
前の記事

新人研修の一環で社内ツールを制作しました 2017.09.20
-
次の記事

専門学校HAL×Aiming 産学連携プロジェクト(前編) 2017.10.16